

Convertir PDF en Word Excel Jpeg : les solutions gratuites
Convertir PDF en Word Excel Jpeg : les solutions gratuites

Vous voulez transformer un PDF en document Word, Excel ou en Jpeg pour récupérer du texte, des tableaux ou des images ? C'est possible et facile, avec des outils gratuits sur PC comme sur Mac, ou avec des services en ligne.
Vous souhaitez récupérer les informations contenues dans un PDF pour les exploiter dans un autre logiciel de bureautique ? Récupérer tout le texte ? Ou uniquement les images ? Ou un simple extrait d'une page ? Ou un long tableau pour enrichir vos propres documents ? C'est possible ! Voici plusieurs solutions, toutes gratuites, qui vous permettront d'effectuer toutes sortes de conversions en quelques clics, pour peu que l'auteur du PDF n'y ait pas ajouté de protection contre la copie.
Comment convertir un PDF avec un service en ligne gratuit ?
Notre solution favorite, quel que soit le format de fichier dans lequel vous souhaitez convertir votre PDF ? Les services en ligne gratuits. D'innombrables sites vous proposent la conversion de fichiers PDF, ils ont même beaucoup d'avantages si vous ne craignez pas de leur confier vos documents, et si vous bénéficiez d'une connexion Internet correcte pour envoyer et recevoir des fichiers.
- Nous en citons quelques-uns ici, mais il en existe beaucoup d'autres : iLovePDF, SmallPDF, EasyPDF, online-convert.com, SodaPDF, PDFCandy, PDF2go, Online2PDF.com, PDF24 Tools…
- Ces services en ligne restent gratuits si vous n'avez pas des quantités astronomiques de PDF à convertir, ou des besoins très spécifiques, ou d'énormes fichiers – opérations pour lesquelles ils vous proposent une prestation payante.
- Tous fonctionnent dans un navigateur Web classique, comme Chrome, Firefox, Edge, Safari ou Opera : vous n'avez donc rien à installer de nouveau sur votre ordinateur que ce soit sous Windows, macOS ou Linux. Il n'est même pas nécessaire de se créer un compte gratuit sur le site pour l'utiliser ponctuellement.
- Tous ces services comportent une belle panoplie d'outils pour fusionner des PDF, diviser des PDF, extraire des pages d'un PDF, compresser ou protéger des PDF, et convertir des documents de tous types en fichiers PDF ou, à l'inverse, pour convertir des PDF dans de nombreux autres formats de bureautique : Word, Excel, PowerPoint, Jpeg, PNG, Gif…
- Si un service en ligne ne produit pas un résultat convaincant, essayez-en un autre ! Il y a parfois de nettes différences en fonction du PDF.
Comment convertir un PDF en document Word gratuitement ?
Si vous souhaitez convertir un PDF au format Word, vous possédez sans doute le traitement de texte de Microsoft : demandez alors à Word (pour Windows ou pour Mac) de réaliser la conversion du fichier PDF. Mais d'autres solutions parfois plus efficaces s'offrent à vous, que nous allons voir aussi.
Quelques remarques, que vous utilisiez Word ou une autre méthode de conversion du PDF :
- Si le texte pouvait être copié/collé dans le PDF, alors vous pourrez le modifier et l'enrichir dans le document Word après conversion.
- Dans le PDF, si le texte était scanné et figurait dans une image, seules certaines solutions – souvent payantes – permettent de le convertir en texte modifiable grâce à l'OCR (optical character recognition ou ROC en français, pour reconnaissance optique de caractères). Word n'assure pas cette fonction.
- Les outils de conversion tentent de conserver la mise en page du PDF en créant dans le document Word des blocs de texte, en plaçant correctement les images dans chaque page, etc.
- Lorsque la mise en page du PDF est complexe, la présentation du document initial n'est pas toujours respectée et les blocs de texte repérés par Word sont parfois difficilement exploitables : essayez dans ce cas l'une des autres méthodes présentées ici.
- Les polices de caractères utilisées dans le PDF original n'étant pas forcément installées sur votre ordinateur, la mise en page ne sera pas respectée à la lettre.
- Si vous ouvrez le PDF dans un traitement de texte comme Word ou LibreOffice, conservez toujours le PDF original et utilisez la fonction "Enregistrer sous…" pour sauvegarder le résultat, ou travaillez sur une copie.
- Un PDF converti en fichier Word peut être ouvert et modifié avec tout traitement de texte compatible Word, nous vous présentons plusieurs excellentes solutions gratuites pour Windows, Mac, Linux, iPhone, tablettes et smartphones Android.
Convertir un PDF en fichier Word avec le traitement de texte Word
Pour convertir un fichier PDF en document Word éditable, la solution la plus simple le plus simple est est d'utiliser Word…
- Si vous disposez d'une version récente de Word pour Windows ou pour Mac, ouvrez tout simplement le PDF dans Word via le menu Fichier > Ouvrir.

- Après un message de mise en garde vous indiquant que la mise en page risque de ne pas être identique à celle du PDF original, celui-ci est converti au format Word et éditable comme tout autre document.
- Si le PDF original ne comporte que des images, le texte que l'on peut lire sur ces images ne sera pas modifiable dans Word (essayez un service en ligne gratuit avec OCR).
- Lorsque vous enregistrez le fichier, Word vous propose d'office de sauvegarder le document dans son propre format plutôt qu'en PDF : acceptez cette suggestion pour ne pas écraser l'original.
Convertir un PDF au format Word avec le traitement de texte LibreOffice
La suite bureautique libre et gratuite LibreOffice sait, elle aussi, importer des PDF et les convertir au format Microsoft Word.
- Installez LibreOffice pour Windows ou Mac et lancez l'application.
- Si vous ouvrez un PDF via la commande Fichier > Ouvrir sans autre précision, le document s'ouvrira dans le module de dessin Draw.
- Pour être sûr(e) que le PDF s'ouvre dans le module de traitement de texte Writer de LibreOffice, cliquez sur le menu Fichier, puis sur Ouvrir et, dans la boîte de dialogue de sélection de fichiers, cliquez sur la liste déroulante Tous les fichiers (*.*).
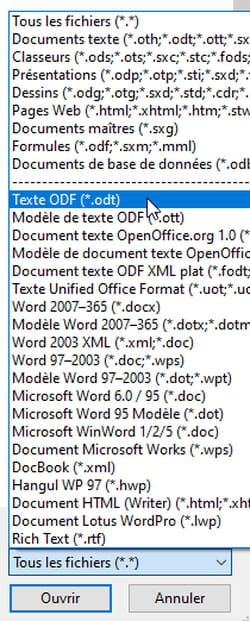
- Repérez la première section qui concerne les formats de fichiers lisibles par Writer : Text ODF (*.odt). Le dernier élément de cette section est PDF – Portable Document Format (Writer), sélectionnez-le.
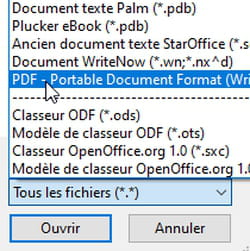
- Choisissez le fichier PDF qui vous intéresse et cliquez sur le bouton Ouvrir… La conversion s'effectue en quelques secondes et le document s'ouvre dans le traitement de texte.
- Dans le menu Fichier, choisissez Enregistrer sous.
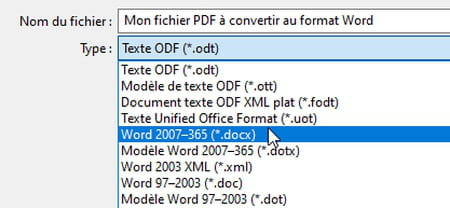
- Dans la liste déroulante Type, sélectionnez Word 2007-365 (*.docx).
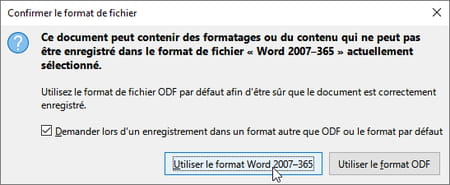
- Confirmez que vous souhaitez Utiliser le format Word 2007-365.
Convertir un PDF en fichier Word avec un service en ligne gratuit
Les services en ligne iLovePDF, SmallPDF, EasyPDF, online-convert.com, SodaPDF, PDFCandy, PDF2go, Online2PDF.com, entre autres, assurent la conversion gratuite de vos PDF en documents Word. Et la plupart le font bien… souvent mieux que Word lui-même !
Bien sûr, même si tous vous promettent la confidentialité et la suppression rapide de vos fichiers une fois convertis, vous hésiterez peut-être à confier vos PDF les plus confidentiels à ces services en ligne. Et, pour une utilisation gratuite, certains limitent le nombre de conversions permises par jour, ou réservent à la version payante du site la reconnaissance optique des caractères OCR.
La demande de conversion est d'une extrême simplicité, avec très peu d'options voire aucune à sélectionner :
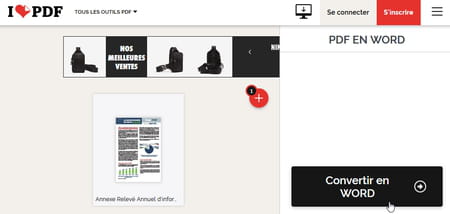
- Dans votre navigateur Web habituel, rendez-vous sur un service en ligne gratuit tel que iLovePDF ou online-convert.com.
- Choisissez dans les menus l'option Convertir PDF en Word.
- Sur certains services en ligne, la conversion vers Word se nomme Convertir en DOC (pour que le fichier converti soit lisible par d'anciennes versions de Word) ou Convertir en DOCX (versions les plus récentes de Word).
- Cliquez sur le bouton Sélectionner le fichier PDF pour le récupérer sur votre disque dur ou attrapez-le dans un dossier Windows/Mac et faites-le glisser sur la page Web. Certains sites vous permettent aussi de piocher un PDF dans votre espace de stockage en ligne Dropbox ou Google Drive.

- À titre d'exemple, le service online-convert.com (illustration ci-dessus) vous permet d'analyser par OCR les images du PDF afin d'en convertir le texte détecté en un texte éditable dans Word. Précisez si votre PDF est en français et si vous préférez une analyse favorisant le respect de la Mise en page ou la précision du Texte.
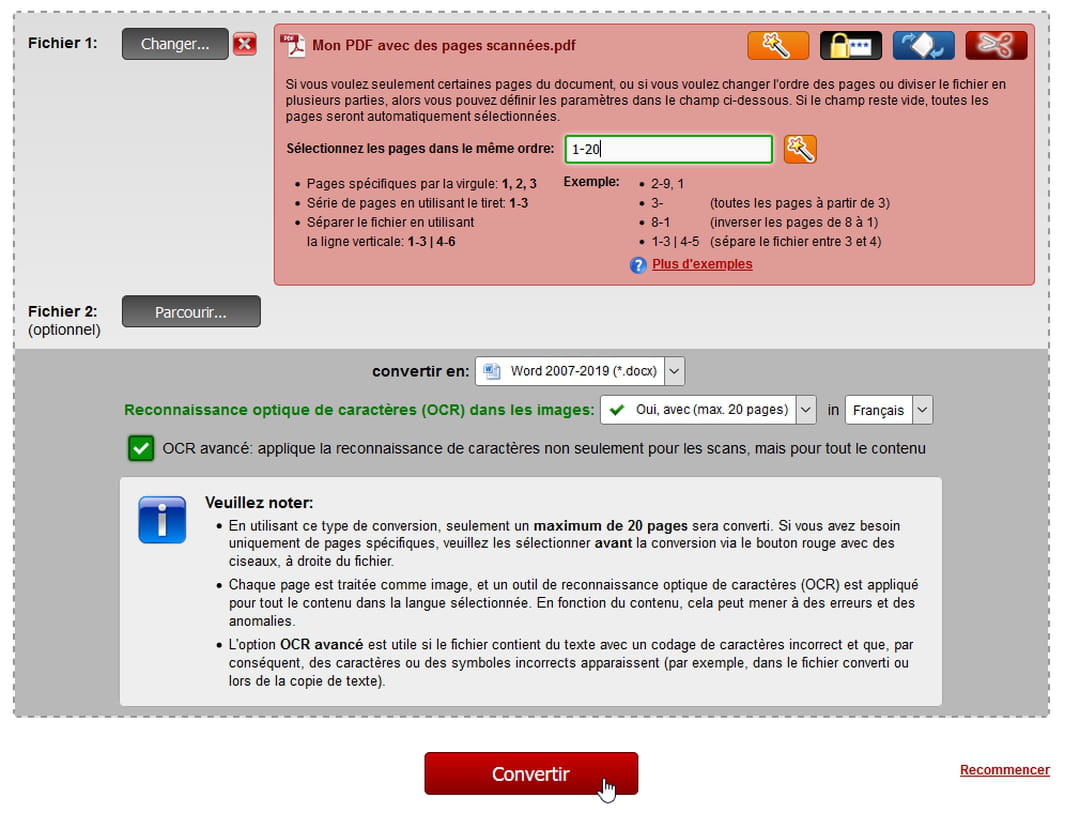
- De son côté, le service en ligne Online2PDF.com (illustration ci-dessus) offre, lui, l'OCR dans les images pour 20 pages de votre PDF que vous lui indiquez, par exemple en précisant 1-20 pour les 20 premières pages, ou 1-3,5-7 pour retenir les pages 1, 2, 3, 5, 6, 7 seulement.
- Cliquez enfin sur le bouton Convertir en Word ou équivalent.
- Après conversion, votre navigateur télécharge en principe automatiquement le fichier au format Word, sinon cliquez sur le bouton Télécharger pour récupérer le fichier sur votre disque dur.
Convertir un PDF en Word avec Google Drive et Google Docs
Si le fichier PDF est sur votre espace Google Drive, il est facile de l'ouvrir dans le traitement de texte en ligne gratuit Google Docs puis de le transformer en document Word.
- Transférez le fichier PDF sur votre espace Google Drive, qui vous réserve 15 Go d'espace de stockage en ligne gratuit pour chaque adresse e-mail que vous créez sur Gmail (autrement dit pour chaque compte Google).

- Cliquez avec le bouton droit de la souris sur le PDF et choisissez Ouvrir avec, Google Docs.
- Modifiez éventuellement le document dans le traitement de texte.
- Pour le convertir au format Word et le télécharger sur votre PC ou Mac, dans Google Docs, cliquez sur le menu Fichier > Télécharger > Microsoft Word (.docx)
Récupérer tout le texte d'un PDF
Si ce n'est pas le document PDF en lui-même qui vous intéresse, avec sa mise en page et ses images, mais uniquement son texte, voici comment faire si vous utilisez le lecteur de PDF gratuit Adobe Acrobat Reader DC pour Windows et Mac.
- Ouvrez le PDF dans Adobe Acrobat Reader DC.
- Dans le menu Fichier, choisissez Enregistrer au format texte (notez que la commande Convertir en Word, Excel ou PowerPoint nécessite un abonnement payant).
- Pressez le bouton Enregistrer.
- Le fichier est généré avec tout le texte contenu dans le PDF, à condition que l'auteur du PDF n'ait pas imposé de restrictions. Le texte perd sa mise en page et tous ses attributs (gras, italique, etc.), et le texte qui était contenu dans les images n'est pas récupéré (pas d'OCR).
- Le fichier converti au format TXT est lisible par tous les traitements de texte pour ordinateurs et smartphones, par le Bloc-notes de Windows, etc.
Comment convertir un PDF en fichier Excel gratuitement ?
Même si votre PDF panache des colonnes de texte, des images et des tableaux, la conversion au format Excel vous permettra de récupérer les tableaux (avec textes et chiffres) sous une forme plus facilement éditable dans Excel.
- Excel pour Microsoft 365 (pour Windows et Mac) et la suite bureautique gratuite LibreOffice ne permettant pas d'ouvrir directement un fichier PDF, passez par une autre solution gratuite, comme les services en ligne.
- Convertissez par exemple votre document PDF grâce à l'un des nombreux services en ligne gratuits, dont iLovePDF, SmallPDF, EasyPDF, online-convert.com, SodaPDF, PDFCandy, PDF2go, Online2PDF.com.
- L'option se nomme souvent Convertir PDF en Excel ou PDF en XLS ou PDF en XLSX.
- Comme pour la conversion de PDF au format Word, certains sites, dont Online2PDF.com, assurent une analyse OCR gratuite du document initial afin de récupérer le texte et les chiffres contenus dans les images du PDF.
- Le classeur obtenu s'ouvre dans Excel aussi bien que dans tout autre tableur gratuit ou suite bureautique pour Windows, Mac, Linux, smartphones et tablettes.
Comment convertir un PDF en présentation PowerPoint gratuitement ?
Nous vous proposons deux méthodes compatibles Mac et PC, hors connexion avec LibreOffice, ou par Internet avec un service en ligne gratuit.
Convertir un PDF en PowerPoint avec LibreOffice
Le logiciel de présentation PowerPoint de Microsoft ne permet pas de lire un PDF pour le convertir à son format (il sait en revanche faire l'inverse : convertir une présentation PowerPoint en un fichier PDF). La suite libre et gratuite LibreOffice, compatible Windows, Mac et Linux, elle, s'en acquitte souvent très bien.
- Installez LibreOffice et lancez l'application.
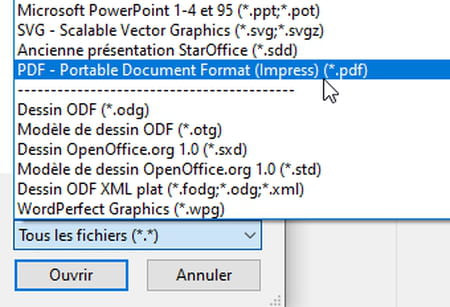
- Dans la fenêtre d'ouverture de fichiers, déroulez la liste indiquant Tous les fichiers (*.*) et faites défiler la longue liste de formats pour choisir PDF – Portable Document Format (Impress) (*.pdf).
- Sélectionnez le PDF sur votre disque dur.
- Il s'ouvre dans le module de présentation Impress de LibreOffice.
- Enregistrez-le via Fichier > Enregistrer sous au format PowerPoint 2007-365 (*.pptx).
Convertir un PDF en PowerPoint avec un service en ligne
Les services en ligne gratuits réalisent pour vous la conversion en quelques secondes…
- Dans votre navigateur Internet, rendez-vous par exemple sur l'un des sites suivants : iLovePDF, SmallPDF, EasyPDF, online-convert.com, SodaPDF, PDFCandy, PDF2go, Online2PDF.com.
- Choisissez dans le menu du site l'option Convertir PDF en PowerPoint ou Convertir PDF en PPT (ou PPTX). Sélectionnez sur votre disque dur le fichier PDF à transformer et lancez la conversion.
- Le fichier PowerPoint obtenu contient autant de pages que le PDF d'origine. La mise en page est souvent fidèle, bien que le changement de polices de caractères implique parfois des différences.
- Le fichier PowerPoint généré est modifiable avec l'application PowerPoint de Microsoft, bien sûr, mais aussi avec de nombreux logiciels de présentation gratuits pour Windows, Mac et Linux, dont la suite bureautique libre LibreOffice.
Comment convertir un PDF en image Jpeg, Gif ou PNG gratuitement ?
Nous allons voir plusieurs méthodes pour Mac et PC, très simples ou plus élaborées.
Faire une capture d'écran d'un PDF avec Windows
Sous Windows 10, si vous souhaitez juste conserver sous forme d'image un extrait d'un PDF visible à l'écran…
- Affichez le PDF dans l'application de votre choix (votre navigateur Internet, Acrobat Reader, Foxit Reader…). Zoomez sur la partie à capturer pour que l'image ait une bonne définition.
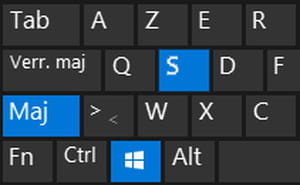
- Pressez les trois touches Windows+Maj+S sur le clavier de votre ordinateur.
- Une mini-fenêtre apparaît en haut de votre écran. La première des cinq icônes, Capture rectangulaire, vous sera sans doute la plus utile : une fois que vous avez cliqué dessus, tracez un rectangle à la souris autour de la zone du PDF que vous voulez conserver au format image.
- Les autres choix possibles sont : Capture de forme libre (avec la souris, tracez un contour personnalisé de la zone à capturer), Capture de fenêtre (cliquez sur l'une des fenêtres ouvertes sur le bureau de Windows pour ne capturer que celle-ci), Capture plein écran (pour obtenir une image de la totalité de votre écran) et Fermer (pour annuler).
- L'image est copiée d'office dans le presse-papiers de Windows. Vous pouvez donc la coller (menu Édition, Coller ou Ctrl+V) dans toute application qui accepte un copier-coller d'une image dans ses documents (logiciel de dessin, Word, Excel, PowerPoint, LibreOffice, etc.).
- Si vous préférez enregistrer l'image sur votre disque dur, cliquez sur la petite fenêtre qui s'affiche dans le coin inférieur droit de l'écran (illustration ci-dessus).

- Vous voilà dans l'application Capture d'écran et croquis, fournie avec Windows 10.
- Vous disposez d'outils pour annoter, surligner, gommer, rogner l'image capturée.
- À droite de la barre d'outils, l'icône représentant une disquette sert à enregistrer le fichier. Le format PNG suggéré par Windows 10 convient parfaitement, il sera lisible par tous les ordinateurs et appareils mobiles, et par toutes les applications capables de lire des images. Mais vous pouvez aussi choisir l'un des deux autres formats proposés, JPG (jpeg) et Gif, ils sont tout aussi universels et lisibles par tout type d'appareil.
Faire une capture d'écran d'un PDF sur Mac
Après avoir ouvert le PDF dans l'application de votre choix, voici comment faire :
- Zoomez sur la partie que vous souhaitez capturer.
- Si vous consultez le PDF dans l'application Aperçu, cliquez sur le menu Fichier > Effectuer une capture d'écran > De la sélection, et tracez un rectangle autour de la zone du PDF à conserver. Enregistrez le fichier image ainsi créé.
- Dans l'application Aperçu, pour convertir la page actuelle du PDF, vous pouvez également dérouler le menu Fichier > Exporter et choisir le Format JPEG. Conservez les valeurs moyennes proposées (ou jouez sur les options de qualité, ce qui a aussi une incidence sur la taille du fichier) et pressez le bouton Enregistrer.
- Une méthode plus générale, qui fonctionne avec toutes les applications… Pressez les trois touches Commande+Majuscule+3 pour capturer la totalité de votre écran, ou Commande+Majuscule+4 pour capturer une zone rectangulaire, que vous tracez à la souris.
- L'image est enregistrée, au format PNG, sur le bureau de macOS.
- Une mini fenêtre montrant l'image capturée apparaît aussi dans le coin inférieur droit de votre écran, cliquez éventuellement dessus pour la modifier.

- Vous disposez de plusieurs outils pour rogner et annoter l'image avant de cliquer sur le bouton Terminé.
Capturer un extrait d'un PDF avec Adobe Acrobat Reader
Si vous utilisez le lecteur de PDF gratuit d'Adobe pour Mac ou Windows et qu'il vous faut juste conserver sous forme d'image un extrait d'une page de PDF…
- Ouvrez le PDF dans Adobe Acrobat Reader.
- Zoomez sur la partie qui vous intéresse, par exemple en pressant la touche Ctrl du clavier tout en faisant rouler la molette centrale de la souris.
- Déroulez le menu Édition et cliquez sur Prendre un instantané.
- Tracez à la souris un rectangle autour de la zone à conserver… l'image est copiée dans le presse-papiers.
- Il vous reste à la coller (Ctrl+V) dans une application de votre choix : logiciel de dessin, traitement de texte, tableur, logiciel de présentation…
Convertir un PDF en image Jpeg avec PDFCreator pour Windows
PDFCreator, de pdfforge, est un logiciel gratuit pour Windows 7, 8, 10. Si vous l'installez sur votre PC, notez qu'il propose l'installation d'applications complémentaires qui nous semblent superflues (pressez le bouton en anglais Decline pour refuser ; une fois dans l'application, rassurez-vous, les menus sont en français). PDFCreator facilite d'abord la conversion de documents de tout type en PDF. Cette application propose un "pilote d'impression virtuel" pour créer un PDF à partir de toute application permettant d'imprimer (Windows 10 propose lui aussi un pilote d'impression virtuel pour créer des PDF).
Quelle que soit votre version de Windows, PDFCreator vous aidera aussi à fusionner plusieurs documents (Word, Excel, PowerPoint, images, PDF…) en un seul fichier PDF, et, ce qui nous intéresse ici, à convertir un PDF entier en autant d'images que le PDF contient de pages.
Cette méthode offre l'avantage de la confidentialité, elle ne vous oblige pas à envoyer vos PDF sur Internet.
- Ouvrez le PDF dans votre lecteur de PDF habituel (votre navigateur Internet, Adobe Acrobat Reader, Foxit Reader…).
- Lancez l'impression du PDF via l'icône Imprimer, ou via le menu Fichier, Imprimer ou via une commande équivalente dans votre application.
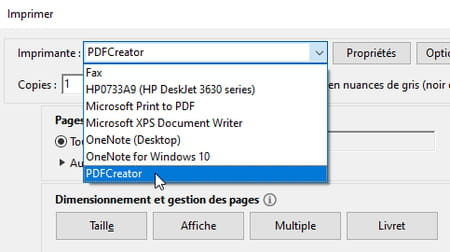
- Dans la boîte de dialogue d'impression, choisissez l'imprimante PDFCreator dans la liste des imprimantes installées sur votre ordinateur.
- Pressez le bouton Imprimer de votre application.
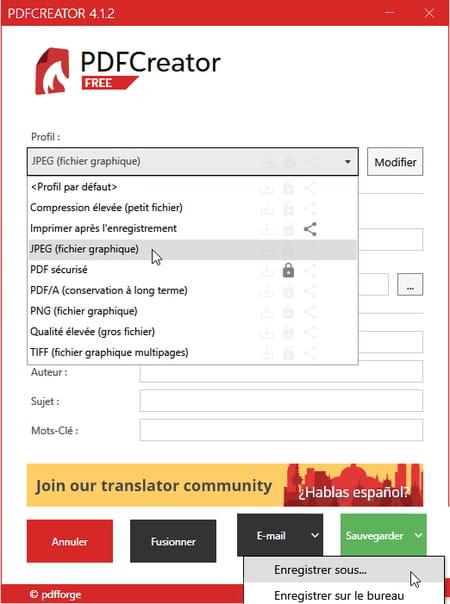
- Une fenêtre de PDFCreator s'ouvre… Dans la liste Profil, choisissez JPEG (fichier graphique) ou PNG (fichier graphique), au choix. En revanche, ne choisissez le format TIFF (fichier graphique multipage) que si vous êtes sûr de disposer d'une application capable d'afficher toutes les pages du fichier graphique Tiff, sinon vous n'en verrez que la première page.
- Précisez le dossier de sauvegarde dans le champ Répertoire avant de presser le bouton Sauvegarder. Ou cliquez sur le chevron à droite du bouton vert Sauvegarder et choisissez Enregistrer sous… pour préciser le dossier.
- PDFCreator génère autant de fichiers Jpeg (ou PNG) que votre PDF contenait de pages, ces images se nomment par exemple MonFichier1.jpg, MonFichier2.jpg, etc.
Convertir un PDF en image Jpeg avec un service en ligne gratuit
Quel que soit le service en ligne que vous choisissez, l'opération est gratuite, au moins sur un nombre restreint de fichiers (ou le site vous impose une limite de taille pour le PDF, par exemple 100 ou 150 Mo, ce qui est déjà généreux), et elle ne prend pas plus de quelques secondes.
- Dans votre navigateur Web pour Windows ou macOS, rendez-vous sur un site spécialisé dans la conversion de PDF : iLovePDF, SmallPDF, EasyPDF, online-convert.com, SodaPDF, PDFCandy, PDF2go, Online2PDF.com, PDF24 Tools…
- Cliquez sur Conversion PDF en JPG ou une option équivalente.
- D'une glissade de souris, attrapez le PDF dans son dossier, sur votre disque dur, et lâchez-le sur la page Web du site de conversion. Ou pressez le bouton Sélectionner le fichier PDF et recherchez votre PDF dans le bon dossier. Le fichier est transféré sur le Web…
- Certains services en ligne convertissent directement les pages du PDF en images Jpeg, d'autres – ci-dessous iLovePDF – vous proposent quelques options simples, par exemple de n'extraire que les images contenues dans le PDF, sans tenir compte du texte (selon le PDF, le résultat n'est pas toujours satisfaisant).

- Si vous avez demandé une conversion complète du PDF en Jpeg, le site produit autant d'images Jpeg (image001.jpg, 002, 003…) que le PDF contenait de pages. Ces fichiers sont stockés dans un seul fichier à télécharger, une archive Zip qu'il vous faudra décompresser.
- Après récupération du fichier Zip, déplacez-le du dossier Téléchargements vers votre dossier de travail et…
- Dans Windows, cliquez avec le bouton droit de la souris sur le fichier Zip pour choisir Extraire tout… (les fichiers images seront sauvegardées dans un sous-dossier du même nom que le Zip).
- Sur Mac, double-cliquez sur l'archive Zip pour créer un sous-dossier décompressé du même nom que le Zip, avec toutes les images Jpeg à l'intérieur.